Scikit-learn sprint in Paris
Three weeks ago, we organized a scikit-learn sprint in the AXA’s offices in Paris. No less than 37 persons attended the sprint during the week. Such effort is equivalent to a 6 man-month! While the sprint was organized by the scikit-learn fondation @ inria, it united a much wider group of contributors and it was funded by other organizations (see below).
Improvements to scikit-learn
This sprint saw the inclusion of many Pull Requests. We give the big lines of what has been achieved:
Major new statistical model: Neighborhood Components Analysis
Neighborhood Components Analysis (NCA) is a supervised metric learning algorithm. As illustrated below, NCA learns a metric which brings closer samples of the same class, minimizing the error classification rate. Thus, NCA is used in both classification and dimensionality reduction: in classification, the decision is taken using the metric learnt instead of the usual Euclidean distance as in k nearest-neighbours (Example), and in supervised dimensionality reduction by using the embedding induced by the truncated covariance matrix minimizing the classification error (Example) (William de Vazelhe). An interesting aspect is that the dimensionality reduction is guided by the labels, unlike most dimensionality reduction algorithms which are unsupervised.
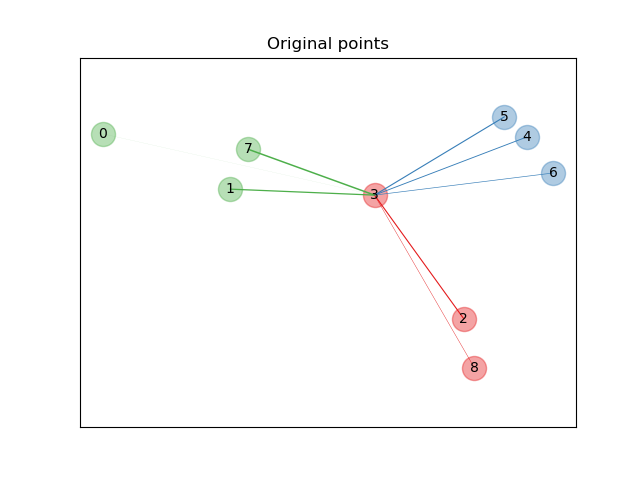 |
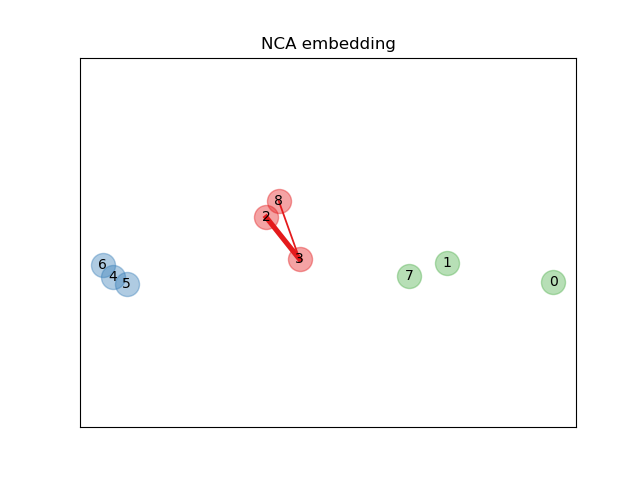 |
New features
- Improvement of one-hot encoder: OneHotEncoder can take a new parameter drop to remove the redundant column created during encoding (PR) (Drew Johnston).
- Better integration with OpenML to fetch dataset: Reduce the memory usage when loading dataset (PR) (Joel Nothman and Joris Van den Bossche).
- Pipeline slicing: Slicing pipeline as in the Python syntax is now supported (PR) (Joel Nothman).
- Improvement of OPTICS API: The API of the OPTICS clustering algorithm has been improved allowing to use the algorithm within a grid-search (PR and PR) (Adrin Jalali and Assia Benbihi).
Ongoing work
- Development of a fast gradient-boosting decision trees algorithm: An approximated GBDT algorithm is proposed (PR) by using histograms (Nicolas Hug).
Release and quality assurance
- ARM 64-bits support: Pull Requests have been submitted to fully support the ARM 64 bits platforms (PR, PR, PR) (Joel Nothman and Roman Yurchak).
- Fitting intercept in linear model: Intercept is now fitted using the sparse conjugate gradient solver in linear and ridge regression. These models will have the same behavior with sparse and dense data (PR, PR) (Alex Gramfort and Bartosz Telenczuk).
- Improving the continuous integration (CI): Significant work to use Microsoft Azure Pipelines (PR) as our main CI was done. Additional Pull Requests have been submitted to improve the usage of the other platforms (PR, PR) (Thomas Fan).
- Release of 0.20.3: A release included multiple bug fixes has been released during the sprint (what’s new).
- Toward release candidate 0.21: Some of the issues addressed are a step further for the next release candidate (milestone).
- Large amount of bug fixes, documentation improvements, and maintenance: In addition of all the previous PRs, a multitude of bug fixes, documentation improvements and fixes have been merged from contributors during the sprint (Danilo Bzdok, Ivan Panico, Maria Telenczuk, and Marine Le Morvan).
Speed & memory usage
- OpenMP support: Support for OpenMP was added. OpenMP is a low-level parallelization scheme which will benefit to some algorithm implementations in the near future (k-means, gradient boosting trees, etc.). Notably, it will allow for implementing nested parallelism (PR, PR) (Jeremie du Boisberranger, Olivier Grisel, and Thomas Moreau).
- Memory efficient algorithms: Some algorithms have been improved by avoiding some conversion of the input data to 64 bits: Linear Discriminant Analysis (PR), Logistic Regression (PR), Isotonic regression (PR) (Joan Massich, Nelle Varoquaux, Thibault Sejourne, and Vlad Nicolae). Some additional improvements were proposed to avoid memory copies when the data type was already the correct one (PR) (Roman Yurchak).
- Better management of parallel processing: Oversubscription can occur during parallel processing: many different parts of the data-processing pipeline use in parallel computing resources. This oversubscription leads to a drastic decrease of performance. This issue is solved for the pairwise distance computation all algorithms which depend of this implementation (PR) (Olivier Grisel, Pierre Glaser, and Romuald Menuet). In addtion, the cython code of the SAG solver has been improved when used in parallel (PR) (Pierre Glaser).
- Improve memory efficiency in isolation forest: Isolation forest became more memory efficient by avoiding storing intermediate tree predictions (PR) (Albert Thomas and Nicolas Goix).
Formalizing the future development:
A scikit-learn sprint is not only about merging Pull Requests and fixing bugs. This sprint gathered a lot of core contributors allowing to focus on higher level issues such as community management and API consistency and development:
- Governance of scikit-learn: The scikit-learn community formalized a governance and decision-making document. This document enforces a complete transparency in the decision process within the project and the community operation.
- Update of the inclusion criteria: Scikit-learn has a strong policy regarding the inclusion of new methods. However, it was decided that we will apply less stringent criteria for new algorithms that speed up an existing model under some circumstances (PR).
- Passing feature name across estimators: A SLEP regarding the support of passing feature name between estimator will be proposed (Andreas Muller and Joris Van den Bossche).
- Allow to resample X and y: A SLEP is proposed to allow resampling X and y within a pipeline (Guillaume Lemaitre and Oliver Raush).
- Add support for sample properties: A SLEP is proposed to be able to give additional per sample information at training (Joel Nothman).
- Freeze estimators: A SLEP about estimator freezing (i.e. estimator which will not update their inner parameter when calling fit) should be proposed (Joel Nothman).
List of participants:

- Adrin Jalali, Ancud IT-Beratung GmbH
- Ahmed Ferjani, AXA
- Albert Thomas, Huawei
- Alexandre Corradin, AXA
- Alexandre Gramfort, Inria Saclay Ile-de-France
- Alexis Gatignol, AXA
- Andreas Mueller, Columbia University
- Assia Benbihi, Georgia Tech Lorraine
- Aurelien Bellet, Inria Lille
- Bartosz Telenczuk, Freelance
- Bertrand Thirion, Inria Saclay Ile-de-France
- Danilo Bzdok, RWTH Aachen
- Gael Varoquaux, Inria Saclay Ile-de-France
- Guillaume Lemaitre, Inria Saclay Ile-de-France
- Ivan Panico, Onepoint
- Jeremie du Boisberranger, Inria Saclay Ile-de-France
- Joan Massich, Inria Saclay Ile-de-France
- Joel Nothman, University of Sydney
- Joris Van den Bossche, Inria Saclay Ile-de-France
- Julien Jerphanion, Dataiku
- Maria Telenczuk, Inria Saclay Ile-de-France
- Marine Le Morvan
- Nicolas Goix, Blockchain
- Nicolas Hug, Columbia University
- Oliver Raush, ETH Zurich
- Olivier Grisel, Inria Saclay Ile-de-France
- Patricio Cerda, Inria Saclay Ile-de-France
- Paul Hureaux, AXA
- Pavel Soriano, Etalab
- Pierre Glaser, Inria Saclay Ile-de-France
- Roman Yurchak, Symerio
- Romuald Menuet, Inria Saclay Ile-de-France
- Samuel Ronsin, Dataiku
- Thibault Sejourne, Ecole Normale Supèrieure
- Thomas Fan, Columbia University
- Thomas Moreau, Inria Saclay Ile-de-France
- William de Vazelhes, Inria Lille
- Xavier Dupre, Microsoft
Acknowledgment

We would like to thank the following sponsors to have give various type of support to make the scikit-learn sprint possible:
- AXA to provide a fantastic venue for a productive coding week;
- Columbia University and the Python Software Foundation for providing a financial support for traveling expenses for some developers and the catering during the sprint;
- All institutions, companies which supported the sprint with their workforces: Ancud IT-Beratung GmbH, AXA, Blockchain, Columbia University, Dataiku, Etalab, Georgia Tech Lorraine, Huawei, Inria, Microsoft, Onepoint, RWTH Aachen, Symerio, University of Sydney;
- All the partners of the scikit-learn@Inria foundation: AXA, BCG Gamma, BNP Paribas Cardif, Dataiku, Inria, Intel, Microsoft, and Nvidia.
Budget
- Columbia University: ~8500 euros for traveling costs of Andreas Muller, Joel Nothman, Nicolas Hug, and Thomas Fan.
- Python Software Foundation: ~3200 euros for catering during the sprint and traveling costs of Adrin Jalali, Joel Nothman, and Oliver Raush.
- AXA also provided some catering

